3. BigDAWG Middleware Internal Components¶
This section describes each Middleware component and their interaction in more technical detail. It is meant for contributors to BigDAWG or for adaptation of the Middleware to your own project or Polystore implementation.
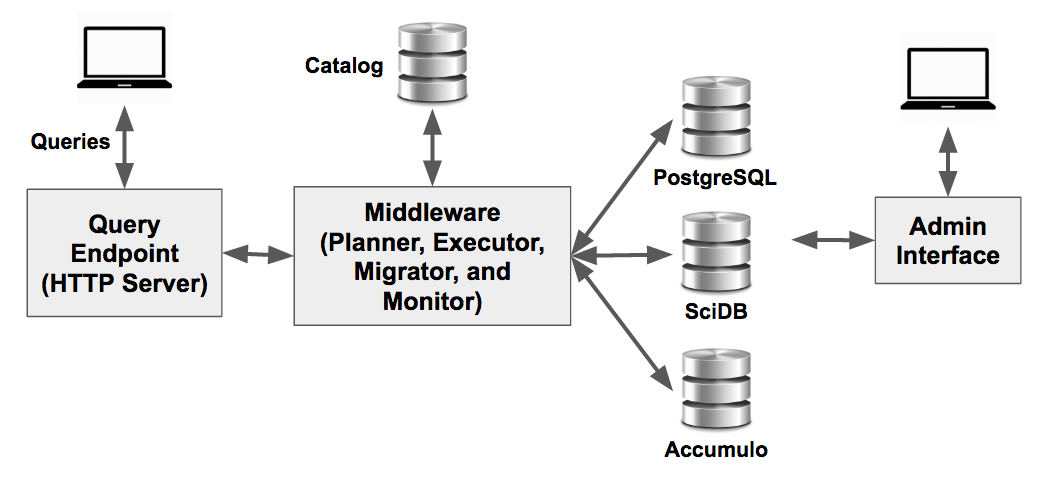
System Overview
The major components of the BigDAWG middleware are shown in the figure above. The sections below provide a technical description of each.
3.1. Query Endpoint¶
The Query Endpoint is responsible for accepting user queries, passing them to the Middleware, and responding with results.
The Query Endpoint is a simple HTTP server that’s executed by the istc.bigdawg.main() method. The hostname/IP address and port used by this server is configurable by setting the following configuration properties:
grizzly.ipaddress=localhost
grizzly.port=8080
See the Getting Started with BigDAWG section or example queries that can be passed to the Query Endpoint. For more information on the syntax of query langage, refer to BigDAWG Query Language.
3.2. Middleware Components¶
The middleware has four components: the query planning module (planner), the performance monitoring module (monitor), the data migration module (migrator) and the query execution module (executor). Given an incoming query, the planner parses the query into collections of objects and creates a set of possible query plan trees that also highlights the possible engines for each collection of objects. The planner then sends these trees to the monitor which uses existing performance information to determine a tree with the best engine for each collection of objects (based on previous experience of a similar query). The tree is then passed to the executor which determines the best method to combine the collections of objects and executes the query. The executor can use the migrator to move objects between engines and islands, if required, by the query plan. Some of the implementation details of each of these components are described below. Please refer to the publications section to learn more.
3.3. Catalog¶
The Catalog is responsible for storing metadata about the polystore and its data objects. The Planner, Migrator, and Executor all rely on the Catalog for “awareness” of the BigDAWG’s components, such as the hostname and IP address of each engine, Engine to Island assignments, and the data objects stored in each engine.
The Catalog is itself a PostgreSQL cluster with 2 databases: bigdawg_catalog and bigdawg_schemas.
3.3.1. bigdawg_catalog Database¶
This database contains the following tables.
enginestable: Engines currently managed by the Middleware, including engine name and connection information.
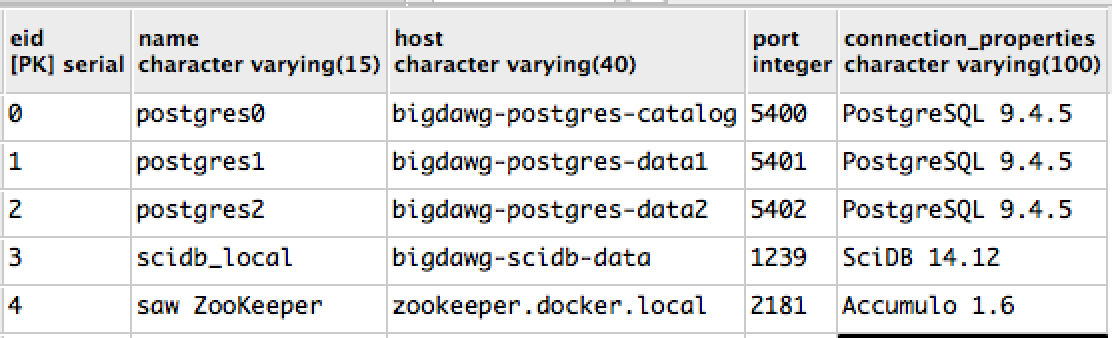
Example Engines Table
databasestable: Databases currently managed by the Middleware, their corresponding engine membership, and connection authentication information.
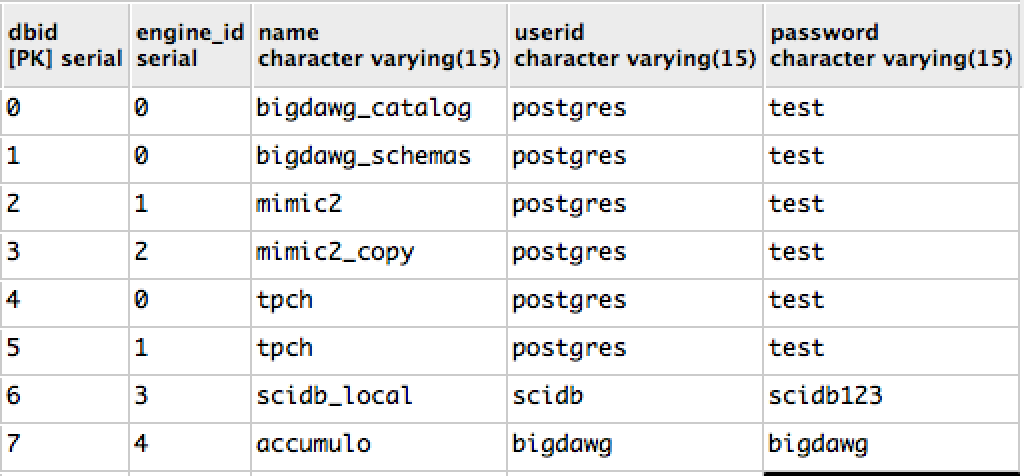
Example Databases Table
objectstable: Data objects (i.e., tables) currently managed by the Middleware, including fieldnames and object-to-database membership.

Example Objects Table
shimstable: Shims describing which engine is integrated into each island.

Example Shims Table
caststable: information about what casts are available between each engine.
3.3.2. bigdawg_schemas Database¶
This database is made up of tables whose column schema define the schema of each data object. For example, the table d_patients from the MimicII dataset has the following schema in the bigdawg_schemas database.
CREATE TABLE mimic2v26.d_patients
(
subject_id integer,
sex character varying(1),
dob timestamp without time zone,
dod timestamp without time zone,
hospital_expire_flg character varying(1)
)
3.4. Planner¶
This section details the Planner. The Planner coordinates all query execution. It has a single static function that initiates query processing for a given query and handles the result output.
package istc.bigdawg.planner;
public class Planner {
public static Response processQuery(
String userinput, boolean isTrainingMode
) throws Exception
}
The String userinput is the string of a BigDAWG query.
When the boolean of isTrainingMode is true, the Planner will perform query optimization by enumerating all possible orderings of execution steps
that will produce an identical result. Then, the Planner sends the enumeration to the Monitor to gather query execution metrics.
The Planner will then pick the fastest plan to run and return the result to the Query Endpoint.
When isTrainingMode is false, the Planner will consult the Monitor to retrieve the best query plan based on past execution metrics.
The processQuery() function first checks if the query is intended to interact with the Catalog.
If so, the query is routed to a specical processing module to parse and process these Catalog-related queries.
Otherwise, processQuery() proceeds to parse and processing the query string.
Data retrieval queries are passed as inputs to the constructor of a CrossIslandQueryPlan object.
A CrossIslandQueryPlan object holds a nested structure that represents a plan for inter-island query execution.
An inter-island query execution is specified by CrossIslandPlanNode objects organized in tree structures: the nodes either carry information
for an intra-island query or an inter-island migration.
Following the creation of the CrossIslandQueryPlan, the Planner traverses the tree structure of CrossIslandPlanNode objects and executes the
intra-island queries, invokes migrations, and then produces the final result.
3.5. Migrator¶
The data migration module for the BigDAWG polystore system exposes a single convenient interface to other modules. Clients provide the connection information for source and destination databases as well as a name of the object (e.g. table, array) to be extracted from the source database, and a name of the object (e.g. table, array) to which the data should be loaded.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | package istc.bigdawg.migration;
/**
* The main interface to the migrator module.
*/
public class Migrator {
/**
* General method (interface, also called facade) for other modules to
* call the migration process.
*
* @param connectionFrom Information about the source
* database (host, port, database name, user name,
* user password) from which the data should be
* extracted.
*
* @param objectFrom The name of the object
* (e.g. table, array) which should be extracted
* from the source database.
*
* @param connectionTo Information about the
* destination database (host, port, database name,
* user name, user password) to which the data
* should be loaded.
*
* @param objectTo The name of the object
* (e.g. table, array) which should be loaded to
* the destination database.
*
* @param migrationParams Additional parameters for the migrator,
* for example, the "create statement" (a statement to create an object:
* table/array) which should be executed in the database
* identified by connectionTo; data should be loaded to this new
* object, the name of the target object in the create statement
* has to be the same as the migrate method parameter: objectTo
*
* @return {@link MigrationResult} Information about
* the results of the migration process (e.g. number of
* extracted elements (rows, cells) from the destination database,
* number of loaded elements (rows, cells) to the destination database,
* the duration of the migration in milliseconds.
*
* @throws MigrationException Information why the migration failed (e.g. no access to one
* of the databases, schemas are not compatible, etc.).
*
*/
public static MigrationResult migrate(
ConnectionInfo connectionFrom, String objectFrom,
ConnectionInfo connectionTo, String objectTo,
MigrationParams migrationParams)
throws MigrationException;
}
}
|
An example of how the data migrator module can be called is presented below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | public class UseMigrator {
public static void Main(String ... args) {
logger.debug("Migrating data from PostgreSQL to PostgreSQL");
FromDatabaseToDatabase migrator = new
FromPostgresToPostgres();
ConnectionInfo conInfoFrom = new
PostgreSQLConnectionInfo("localhost", "5431",
"mimic2", "pguser", "test");
ConnectionInfo conInfoTo = new
PostgreSQLConnectionInfo("localhost", "5430",
"mimic2", "pguser", "test");
MigrationResult result;
try {
result = migrator.migrate(conInfoFrom,
"mimic2v26.d_patients",
conInfoTo, "mimic2v26.d_patients");
} catch (MigrationException e) {
logger.error(e.getMessage());
}
logger.debug("Number of extracted rows: "
+ result.getCountExtractedElements()
+ " Number of loaded rows: " +
result.getCountLoadedElements());
}
}
|
Internally, the Migrator identifies the type of the databases by examinig the connection information.
The ConnectionInfo object is merely an
interface and we check what the real type of the object is.
The connection object represents a specific database (e.g.
PostgreSQL, SciDB, Accumulo or S-Store).
Currently, we support migration between instances of PostgreSQL,
SciDB and Accumulo. There is an efficient binary
data migration between PostgreSQL and SciDB. We work on
distributed migrator (at present it works between instances
of PostgreSQL) and tighter integration with S-Store as well as more
efficient connection with Accumulo.
3.5.1. Binary migration¶
The data transformation module, which converts data be- tween different (mainly binary) formats, is the important part of the data migrator. This module is implemented in C/C++ to achieve high performance. The binary formats require operations at the level of bits and bytes. Many data formats apply encoding to values of attributes in order to decrease storage footprint.
To build the C++ migrator navigate to: bigdawgmiddle/src/main/cmigrator/buil in the maven project.
We use CMake to build this part of the project. Simply execute:
cd bigdawgmiddle/src/main/cmigrator/build
cmake ..
make
3.6. Executor¶
The Executor executes intra-island queries through static functions.
The static functions create instances of PlanExecutor objects that execute individual intra-island queries.
package istc.bigdawg.executor;
public class Executor {
public static QueryResult executePlan(
QueryExecutionPlan plan,
Signature sig,
int index
) throws ExecutorEngine.LocalQueryExecutionException, MigrationException;
public static QueryResult executePlan(
QueryExecutionPlan plan
) throws ExecutorEngine.LocalQueryExecutionException, MigrationException;
public static CompletableFuture<Optional<QueryResult>> executePlanAsync(
QueryExecutionPlan plan,
Optional<Pair<Signature, Integer>> reportValues
);
}
The PlanExecutor objects are created from QueryExecutionPlan objects that represent execution plans of an intra-island query.
A QueryExecutionPlan holds details of sub-queries that are required for their execution and a graph that provides dependency information among the sub-queries.
The PlanExecutor takes information from a QueryExecutionPlan object and issues the sub-queries to their corresponding databases and calls the appropriate
Migrator classes to migrate intermediate results.
package istc.bigdawg.executor;
class PlanExecutor {
/**
* Class responsible for handling the execution of a single QueryExecutionPlan
*
* @param plan
* a data structure of the queries to be run and their ordering,
* with edges pointing to dependencies
*/
public PlanExecutor(
QueryExecutionPlan plan
)
}
3.7. Monitor¶
The BigDAWG monitor is responsible for managing queries.
1 2 3 4 5 | class Monitor {
public static boolean addBenchmarks(Signature signature, boolean lean);
public static List<Long> getBenchmarkPerformance(Signature signature);
public static Signature getClosestSignature(Signature signature);
}
|
The signature parameter is provided to identify a query.
The addBenchmarks method adds a new benchmark.
If the lean parameter is false, the benchmark is immediately run over
all of its possible query execution plans (henceforth referred to as QEP).
The getBenchmarkPerformance method returns a list of execution times for a particular benchmark, ordered in same order that the benchmark’s QEPs are received.
The best way to use the module is to add all of the relevant benchmarks first using the addBenchmarks method and then
retrieve information through getBenchmarkPerformance.
One of the more useful features is contained in the getClosestSignature method, which tries to find the closest matching benchmark for
the provided signature. In this way, a user can add many benchmarks that are believed to cover the majority of query use cases.
Then you use the getClosestSignature method to find a matching benchmark and compare the QEP times to your current signature’s QEPs.
On missing any matching signatures, you can add the current signature as a new benchmark.
There are many opportunities to enhance this feature to improve the matching, possibly by utilizing machine learning techniques.
The public methods in the Monitor class are the only API endpoints that should be used.
In contrast, the MonitoringTask class updates the benchmark timings periodically and should be run in the background through a daemon.