1. Introduction and Overview¶
1.1. Team¶
BigDAWG is an open source project from researchers within the Intel Science and Technology Center for Big Data (ISTC). Everything we do at the ISTC is open intellectual property so anyone is free to use whatever we produce.
The ISTC is based at MIT but includes researchers from Brown University, the University of Chicago, Northwestern University, the University of Washington, Portland State University, Carnegie Mellon University, the University of Tennessee, and, of course, Intel.
1.2. Polystore Systems¶
The slogan is now famous in the database community. “One size does not fit all”. If data storage engines match the data, performance of data intensive applications are greatly enhanced. We’ve done significant performance analsys and have found that using the right storage engine for the job can give you orders of magnitude in performance advantage. Even beyond performance advantages, often organizations already have their data spread across a number of storage engines. Writing connectors across N different systems can lead to a lot of work for developers and make the cost of adding a new system very high.
This has led us to develop database technologies we call “Polystore Systems.” A polystore system is any database management system (DBMS) that is built on top of multiple, heterogeneous, integrated storage engines. Each of these terms is important to distinguish a Polystore from conventional federated DBMS.
Obviously, a polystore must consist of multiple data stores. However, polystores should not to be confused with a distributed DBMS which consists of replicated instances of a storage engine sitting behind a single query engine. The key to a polystore is that the multiple storage engines are distinct and accessed separately through their own query engine.
Therefore, storage engines must be heterogeneous in a polystore system. If they were the same, it would violate the whole point of polystore systems; i.e. the mapping of data onto distinct storage engines well suited to the features of components of a complex data set.
Finally, the storage engines must be integrated. In a federated DBMS, the individual storage engines are independent. In most cases, they are not managed by a single administration team. In a polystore system, the storage engines are managed together as an integrated set. This is key since it means that in a polystore system, you can modify engines or the middleware managing them such that “the whole is greater than the sum of their parts.”
The challenge in designing a polystore system is to balance two often conflicting forces.
- Location Independence: A query is written and the system figures out which storage engine it targets.
- Semantic Completeness: A query can exploit the full set of features provided by a storage engine.
The BigDAWG project described in this document is our reference implementation of this polystore concept. As we will see in the next section, BigDAWG uses the concepts of “islands” to balance these forces.
1.3. BigDAWG Approach¶
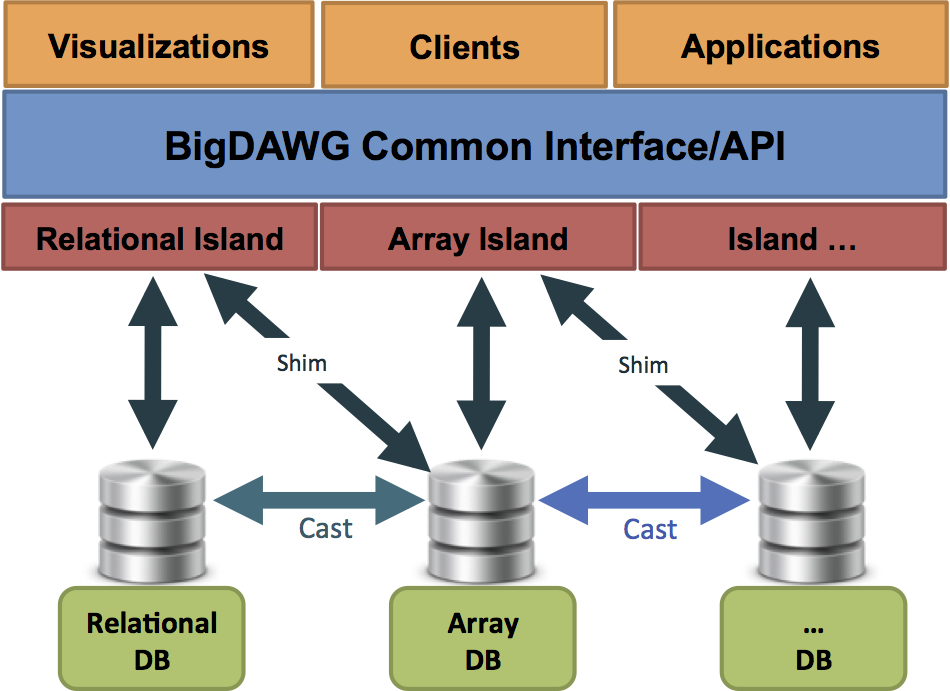
BigDAWG Architecture
Figure 1 describes the overall BigDAWG architecture. This figure is a representation of the BigDAWG polystore system integrated with higher level components to solve end-user applications. At the bottom, we have a collection of disparate storage engines (we make no assumption about the data model, programming model, etc. of each of these engines). These are organized into a number of islands. An island is composed of a data model, a set of operations and a set of candidate storage engines. An island provides location independence among its associated storage engines.
A shim connects an island to one or more storage engines. The shim is basically a translator that maps queries expressed in terms of the operations defined by an island into the native query language of a particular storage engine.
A key goal of a polystore system is for the processing to occur on the storage engine best suited to the features of the data. We expect in typical workloads that queries will produce results best suited to particular storage engines. Hence, BigDAWG needs a capability to move data directly between storage engines. We do this with software components we call casts.
1.4. Major BigDAWG Components¶
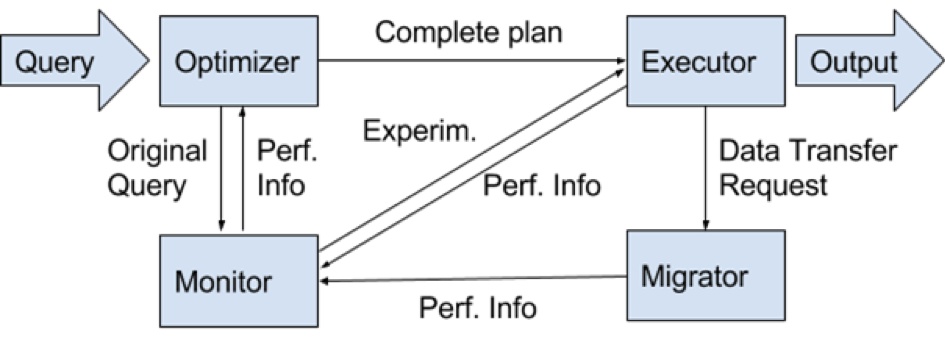
Internal Components of the BigDAWG Middleware
BigDAWG is at its core middleware that supports a common application programming interface (API) to a collection of storage engines. The middleware contains a number of key elements:
- Optimizer: parses the input query and creates a set of viable query plan trees with possible engines for each subquery
- Monitor: uses performance data from prior queries to determine the query plan tree with the best engine for each subquery.
- Executor: figures out how to best join the collections of objects and then executes the query.
- Migrator: moves data from engine to engine when the plan calls for such data motion.
Each of these components will be described in more detail in a later section.
1.5. MIMIC II dataset¶
to demonstrate BigDAWG in action, we are using data collected by the PhysioNet group (https://physionet.org/mimic2/). The MIMIC II dataset contains medical data collected from medical ICUs over a period of 8 years. The MIMIC II datasets consists of structured patient data (for example, things filled in an electronic health record), unstructured data (for example, of the nurse/doctor reports), and time-series waveform data (for example, data collected from different machines one may be connected to while in the EHR). The MIMIC II dataset is a great example of where a polystore solution may work well. The structural parts of the data can sit well in a traditional relational database, the free-form text in a key-value store and the time series waveforms in an array database.
In this release, we provide simple scripts to download this data and load it into appropriate databases. While we only leveraging data the unrestricted parts of the data that do not require registration, we recommend you take a look at Getting Access to the Full Dataset . Also, if you are using any of their data in your results, please be sure to cite them appropriately.